梦晨 发自 凹非寺
量子位 | 公众号 QbitAI
免费猜字小游戏Wordle正在席卷全球,火到以数百万美元的价格被收购,全球玩家数量也突破了200万。
如果你在微博、微信等地方看到这些神神秘秘的方块,那就是Wordle玩家在分享自己当日的战绩了。
根据统计,大多数人类玩家需要猜测4次或以上才能取得胜利。
比如,2月5日的题目在当天30多万份晒出战绩的玩家中,只有27%能在三次以内猜中。
这个游戏自然也成了程序员们的新竞技场,他们写出各种算法来比拼谁用的步数最少。
这其中,百万粉数学科普大神3Blue1Brown的玩法更为硬核——
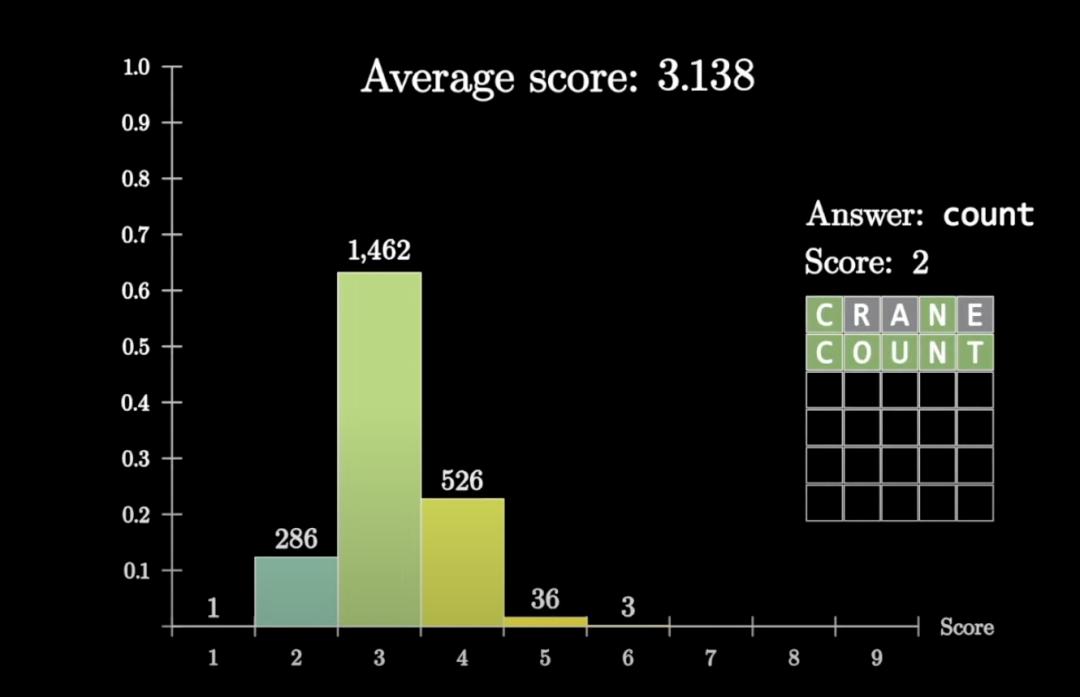
他不光写出了求解算法,还用数学知识一步步优化至逼近理论极限,最终成绩平均3.138次猜测就能获胜。
并且他用统计办法找出了与人类常见策略不同的最佳开局单词crane。
他像往常一样把这个过程整理成视频分享出来,不仅展示了算法,还把其中涉及的信息论、统计学知识讲得明明白白。
视频发布一天之内就有上百万播放,围观的网友也纷纷在评论区表达了赞叹。
为了游戏点进来,为了精彩的信息论知识留下,太酷了!
他用了什么样的算法,理论极限又是怎么算出来的?下面一起来看看。
从每一次猜测中获得最多信息
Wordle的游戏规则很简单,玩家需要猜出程序每天指定的一个5位英语单词谜底。
玩家可以随意提交一个英语单词,但必须是字典里有的,不能胡乱拼写。
如果字母在谜底中出现且位置对了就显示绿色,字母出现了但位置不对就显示黄色,字母在答案的单词中没出现就显示灰色。
根据反馈信息再进行下一轮猜测,在6次尝试之内猜出就算赢。

如何让步数尽量少?
3Blue1Brown的总体思路是尽量从每一次猜测中获得最多的信息。
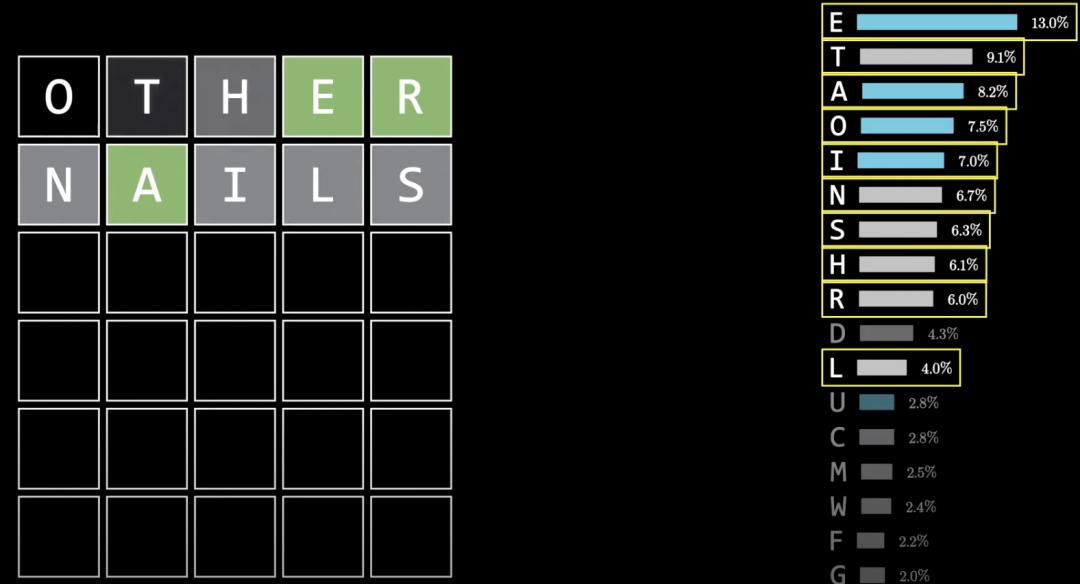
他先是找来了26个字母在英语文本中出现频率的统计数据,尝试在前两次尝试中覆盖最多高频字母。
比如other+nails的组合,就可以覆盖出现频率最高的11个字母中的10个,如果运气好就能确定下来一些字母。
即使这些字母都没出现依然是一种信息量很大的反馈,10个常用字母都没出现的单词数量就大大减少了,让下一步猜测更简单。
不过在尝试过程中,又出现了新的问题。
同样用nails这几个字母,也可以拼成snail ,这两种拼写顺序之间的差异,仅依据字母频率数据是无法衡量的。
下面需要一种新的计算方法。
如何计算信息量?
原版Wordle游戏里有一个数量12972的总单词列表,都能作为猜测词使用。
另外有一个2315个单词的列表,只有这些单词会出现在答案里(据说是游戏作者的女朋友挑选的)。
因为游戏是用Javascript写的,数据都在客户端,这些数据直接可以从源码里找到。
不过3Blue1Brown觉得让程序利用答案列表的话有点像作弊了,他果断给自己加大难度,只考虑总单词列表。
游戏中,每一次猜测都能从12972个单词中排除一些结果。
比如猜测weary,如果W位置正确同时A出现了,那么剩下的可选单词只剩58个。

这样对同一个猜测,从5个字母全没出现到5个字母全对的各种反馈的概率都可以计算出来。
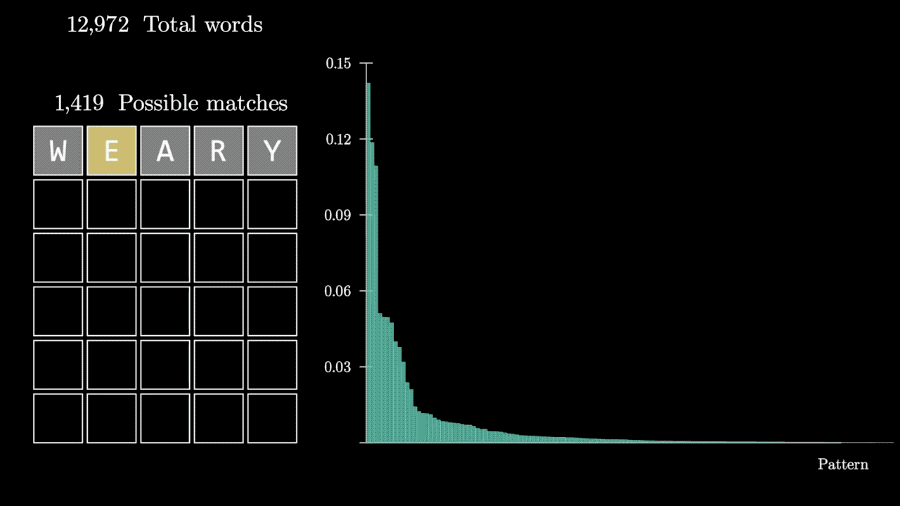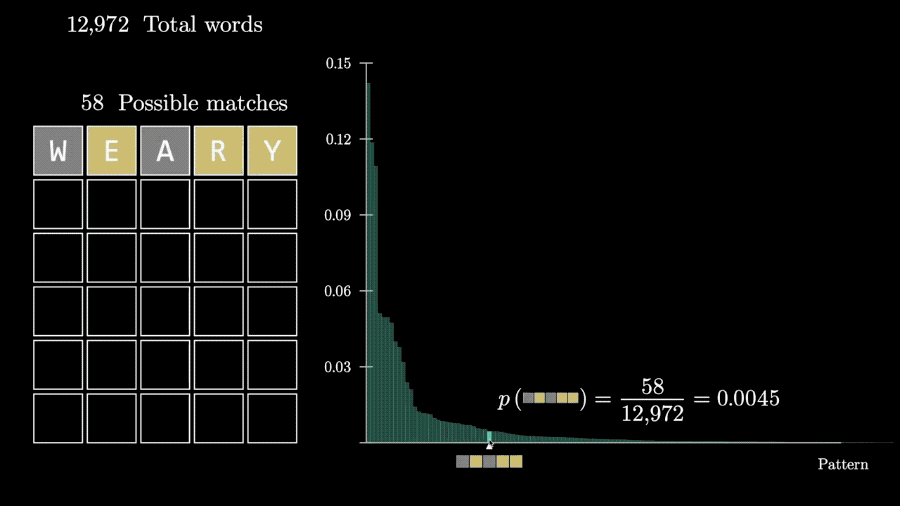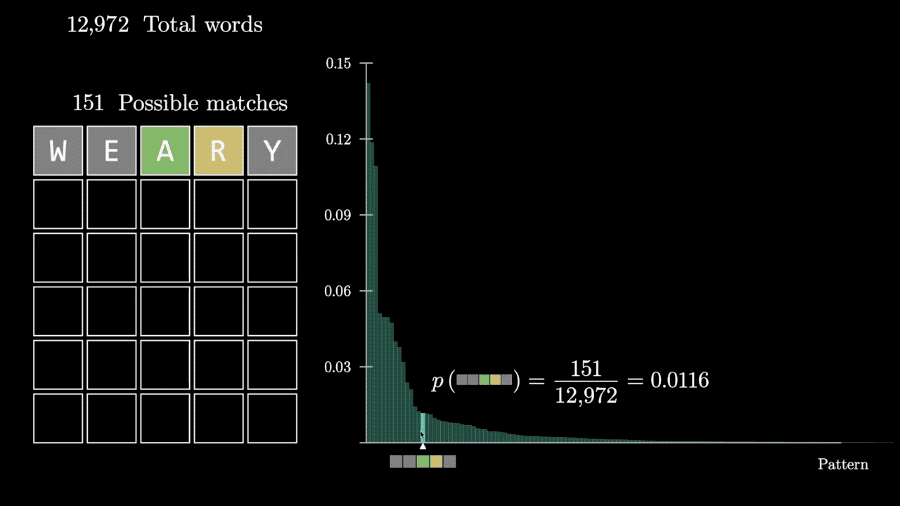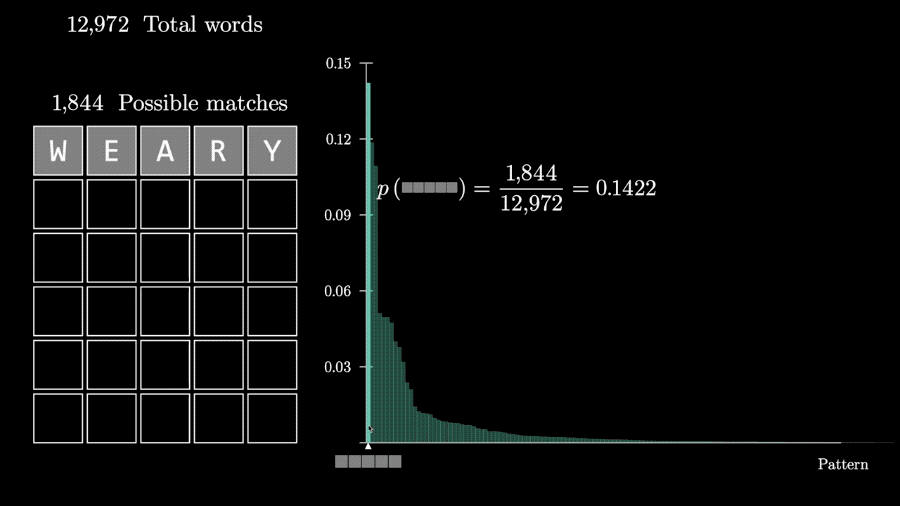
这样,问题就变成了如何评估各种反馈情况包含的信息量。
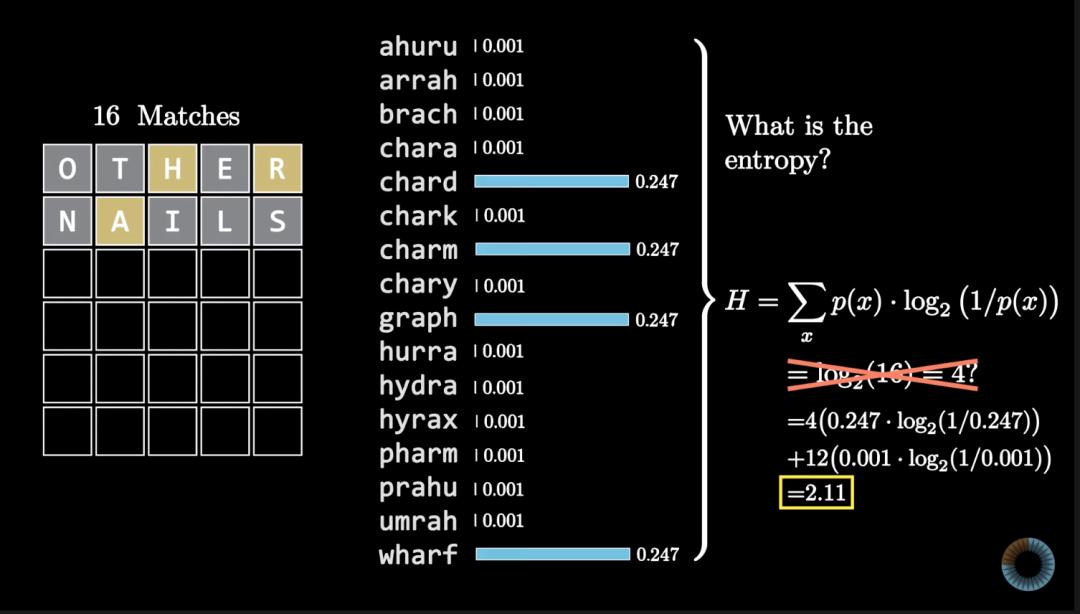
3Blue1Brown选择的办法,就是利用信息论祖师爷香农提出的信息熵概念。
信息熵描述的是事件的不确定性,单位就是大家知道的比特。
理解起来也不难,可以用扔硬币来解释。
扔1枚硬币只会出现正、反两种结果,而且概率相等。
扔2枚硬币就有正正、正反、反正、反反这4种结果,扔3枚有8种情况等等,也就是扔n次有2的n次方种结果。
当一个事件有两种结果且概率都是1/2,其不确定性相当于扔1枚硬币,此时信息熵定义为1比特。
如果一个事件有8种结果且概率都是1/8,就相当于扔3枚硬币,此时信息熵就是3比特。
信息量和信息熵的数量相等、意义相反,相当于衡量一则信息能消除多少不确定性。
设每种结果的概率为p,信息量为I,有如下等式。
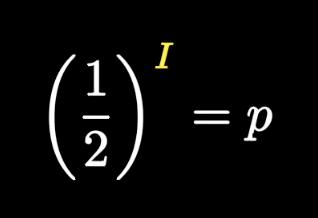
稍作变换,可以得到信息量的计算公式。
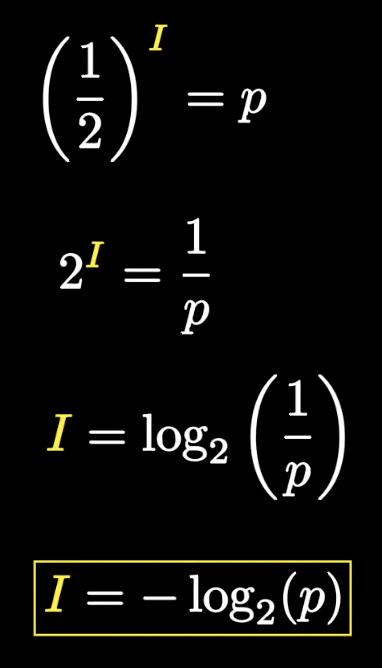
回到Wordle游戏上,一次猜测获得的信息量可以用每种可能情况的概率与对应信息量相乘、再把结果相加来计算,也就是求数学期望。
以猜测weary为例,计算出获得的信息量为4.9比特。
代表这则信息消除的不确定性比扔5个硬币的不确定性少一点。
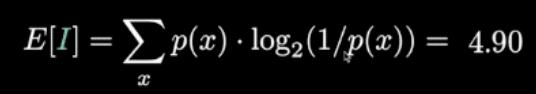
算法思路有了,接下来就可以交给程序,计算出所有12972个单词的能消除的信息熵。
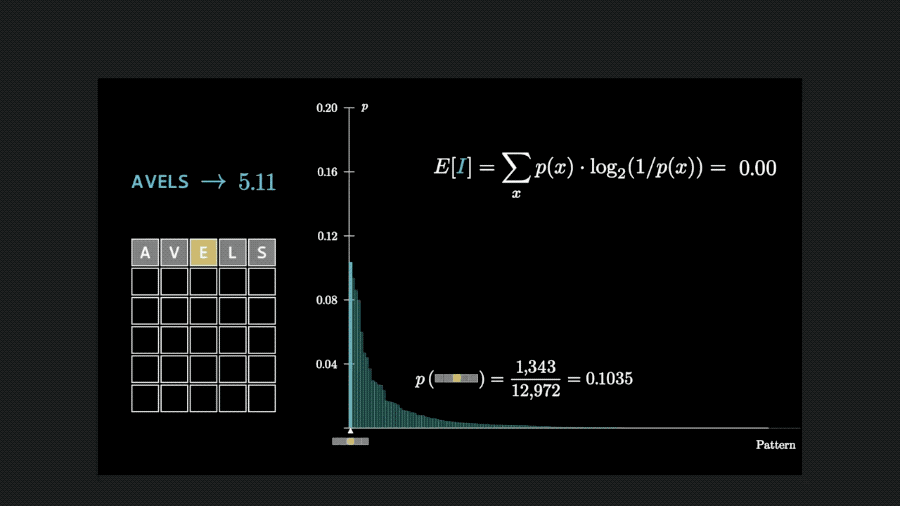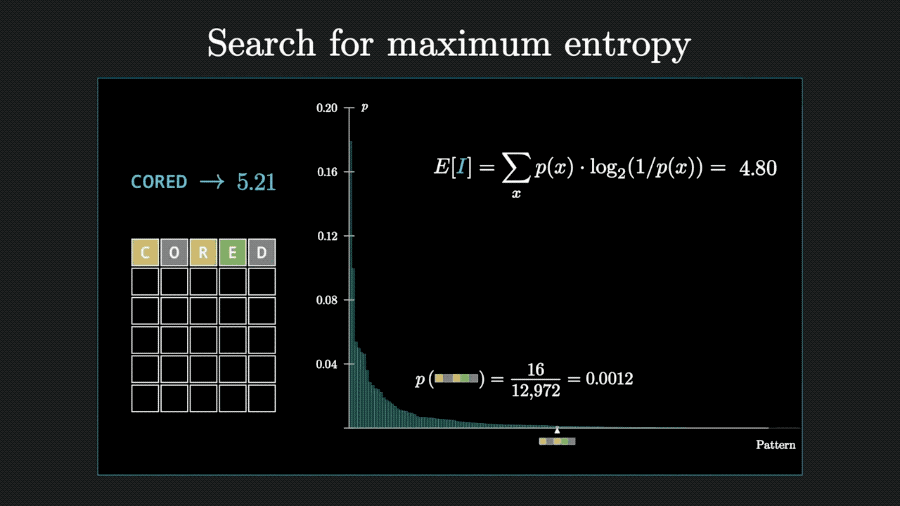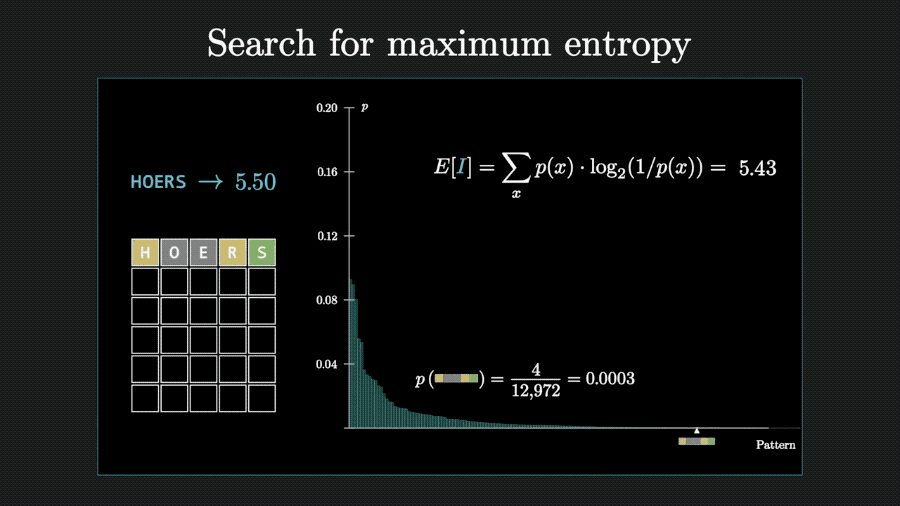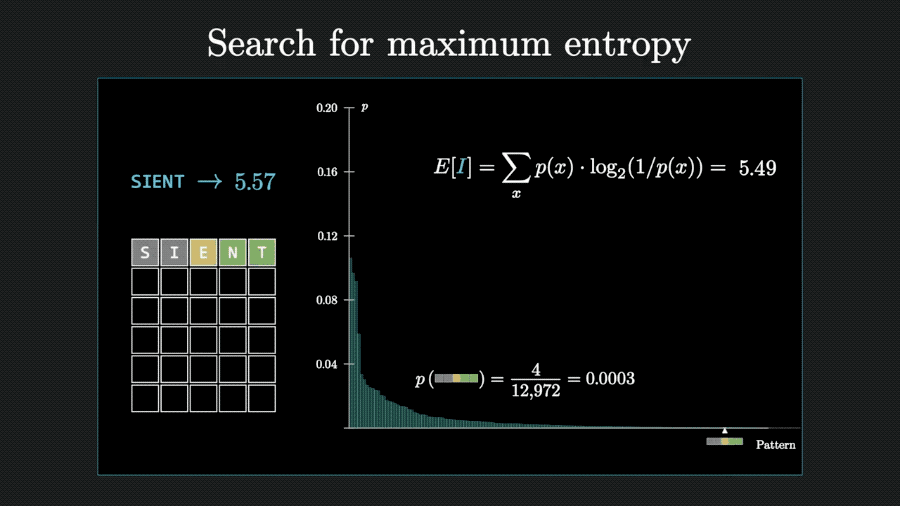
用同样的方法,可以再计算第二步、第三步猜测能消除的信息熵。
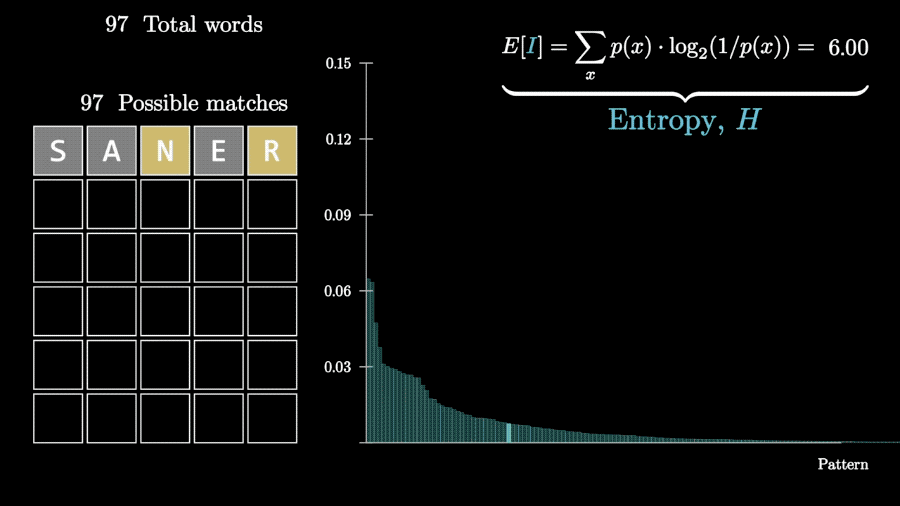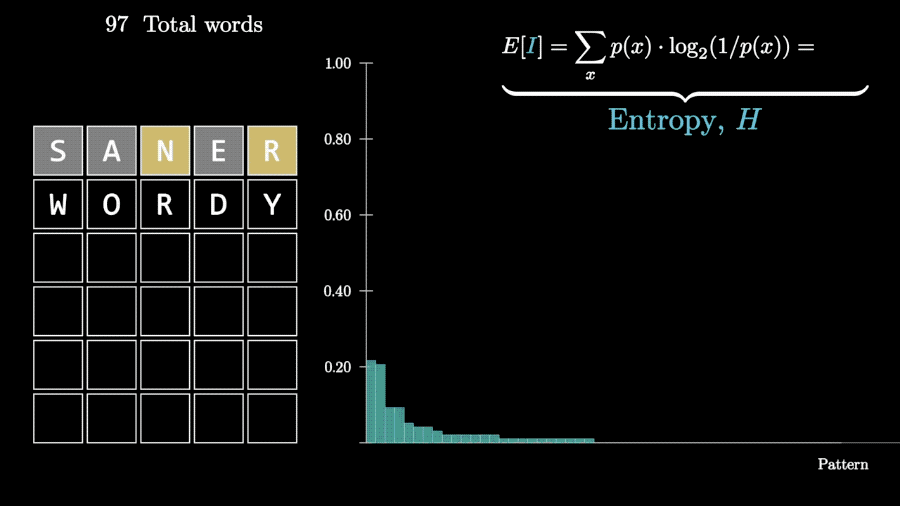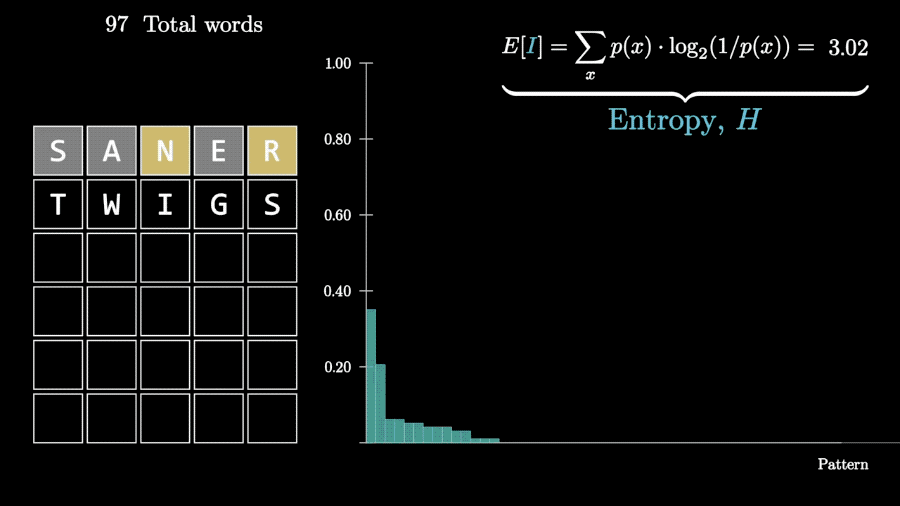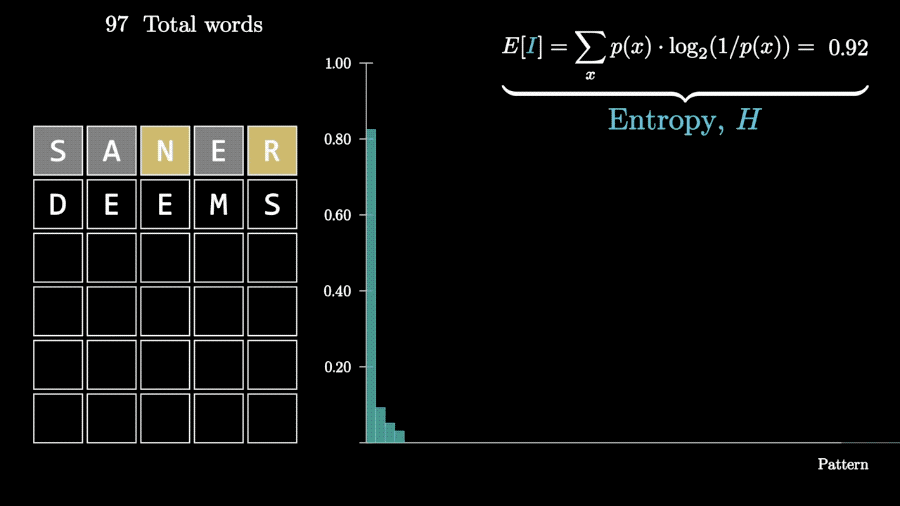
根据这些计算结果,程序就可以在每一次猜测时,选择所有可能单词里能消除信息熵最多的那个。
比如第一次猜slate获得一次反馈,此时还剩下578个单词可选,其中选ramin能消除最多的信息熵,这样一步一步猜直到猜出正确答案。
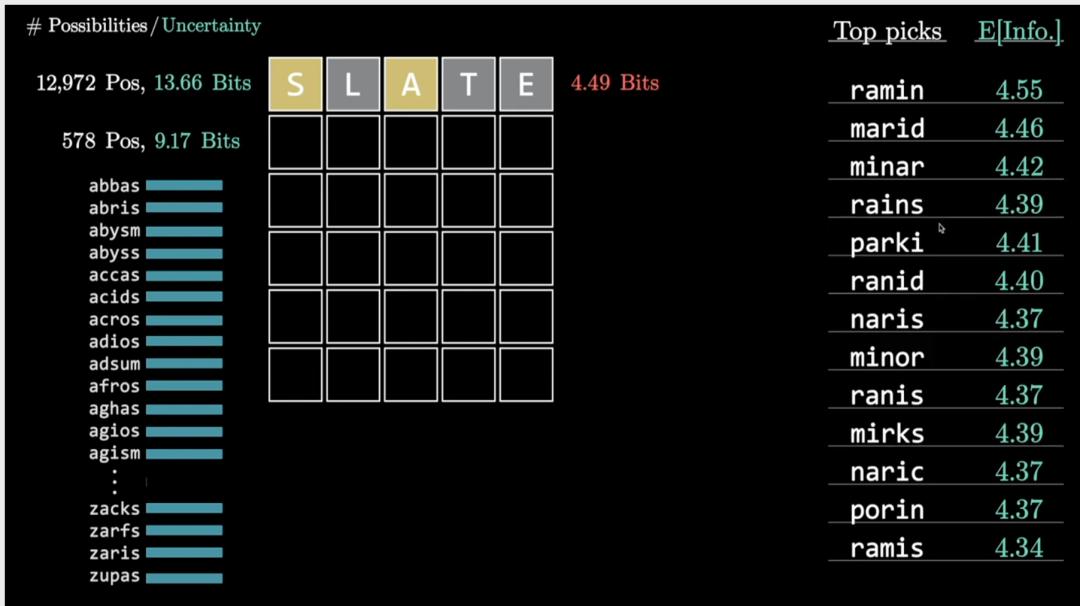
接下来,拿这个程序在所有2135种可能的答案上跑一遍,平均用了4.124步猜出正确答案。
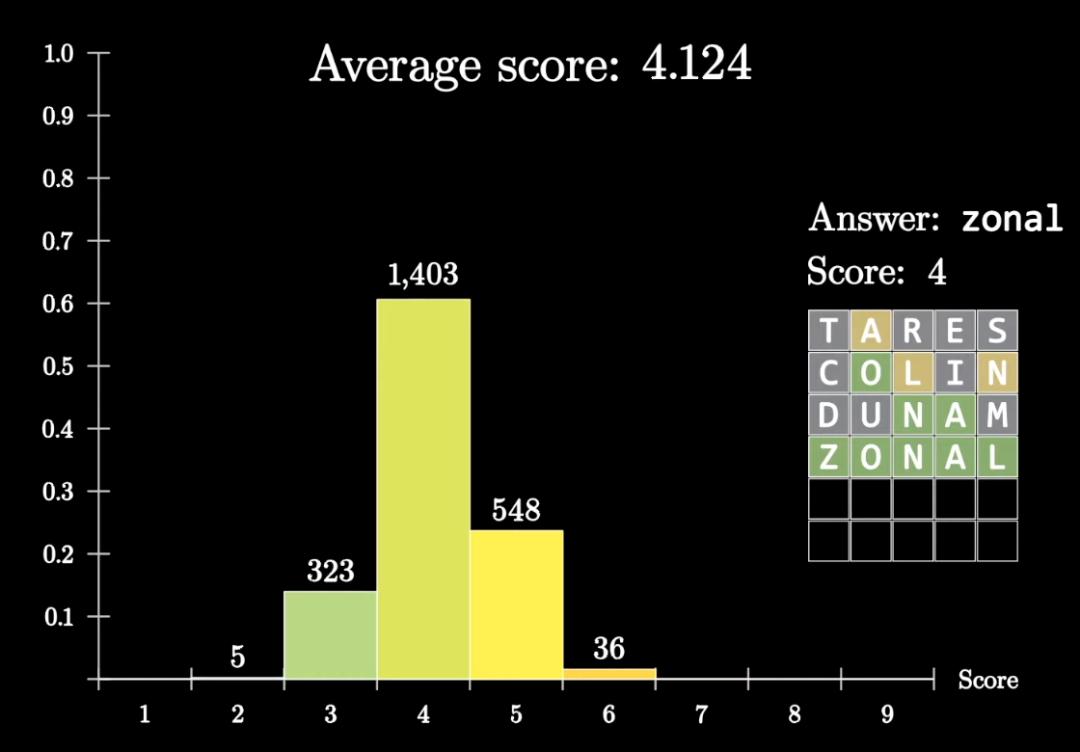
3Blue1Brown觉得这个成绩还不够好,至少没有超过普通人类玩家水平,还需要继续优化。
最终成绩逼近理论极限
成绩不够好的一个问题出在每个单词作为答案的可能性其实并不相同。
像aahed aalii aargh这种偏门单词虽然在允许猜测的总单词列表里,但并不在答案列表的2315个单词里。
找一个典型的例子,当遇到abbas(人名,阿巴斯)和abyss(深渊)二选一时,如果程序能知道abyss是常用词,就可以省下一步。
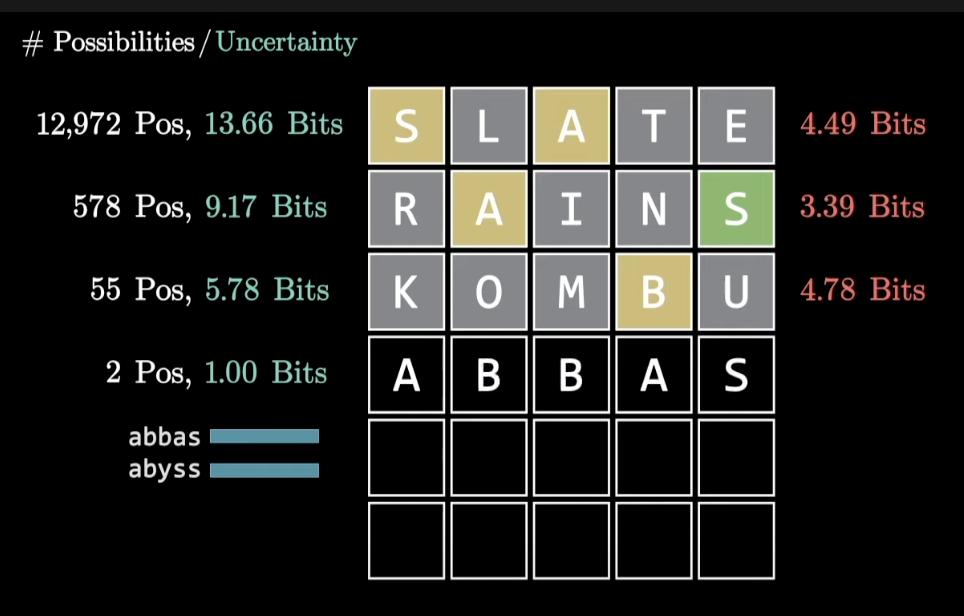
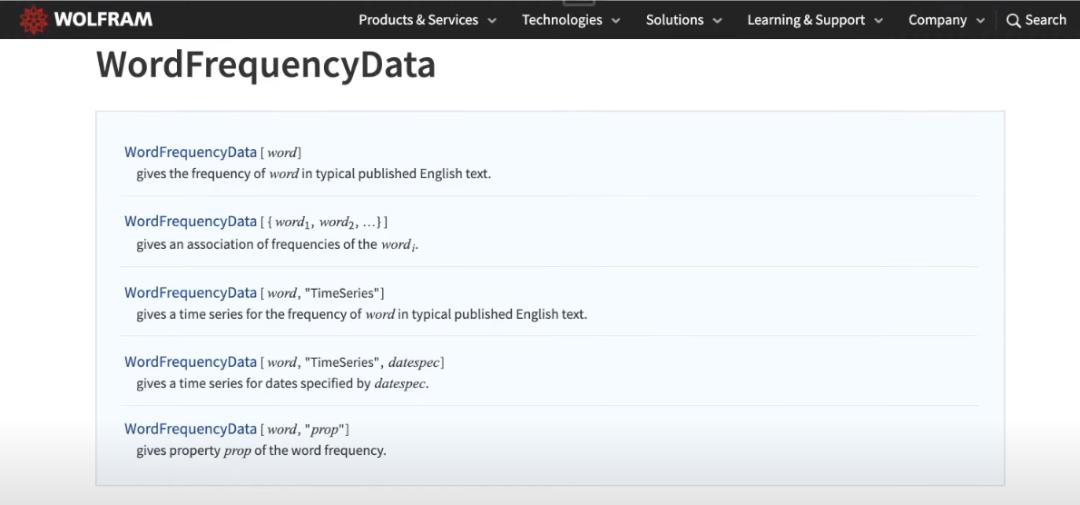
下一步改进方向就是引入词频统计数据,这样的数据集可以从Wolfram上找到。
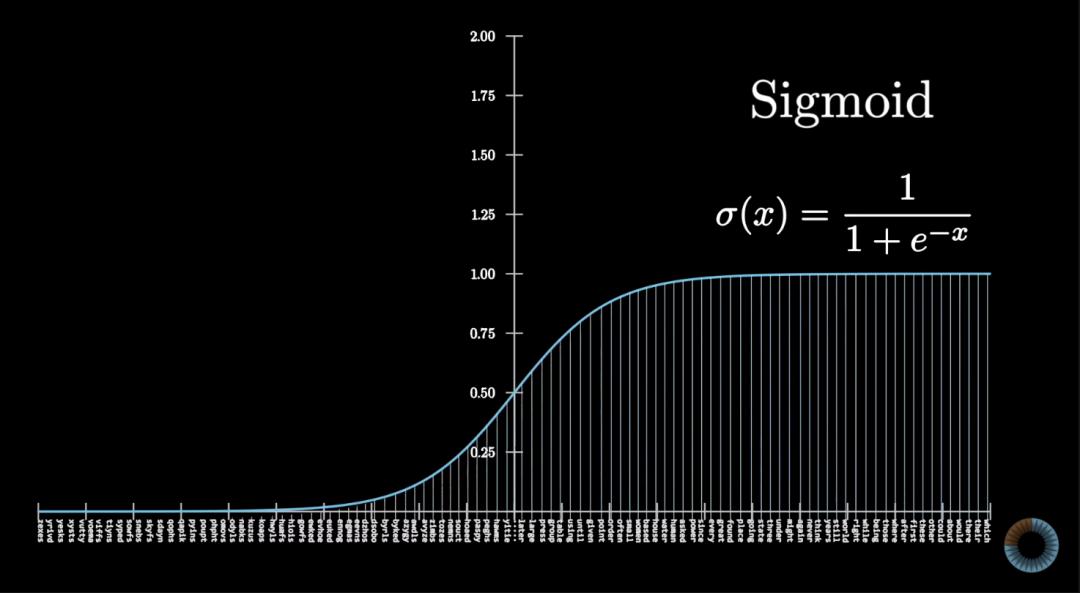
这里还遇到一个问题,比如which和braid的出现频率相差1000倍,但都可以算是常见单词,出现在答案列表里的可能性相差不大。

解决办法就是用Sigmoid函数做处理,让更多数据靠近0或1。
将处理后的词频数据与前面的信息量计算结果相结合,得到优化后的信息量计算方法。
在实际游戏中,也把信息量与词频结合考虑,就能让程序更倾向于选择常见单词。
比如在下面的情况中,words和dorms的信息量并不是最高的,但因为词频较高所以优先考虑。
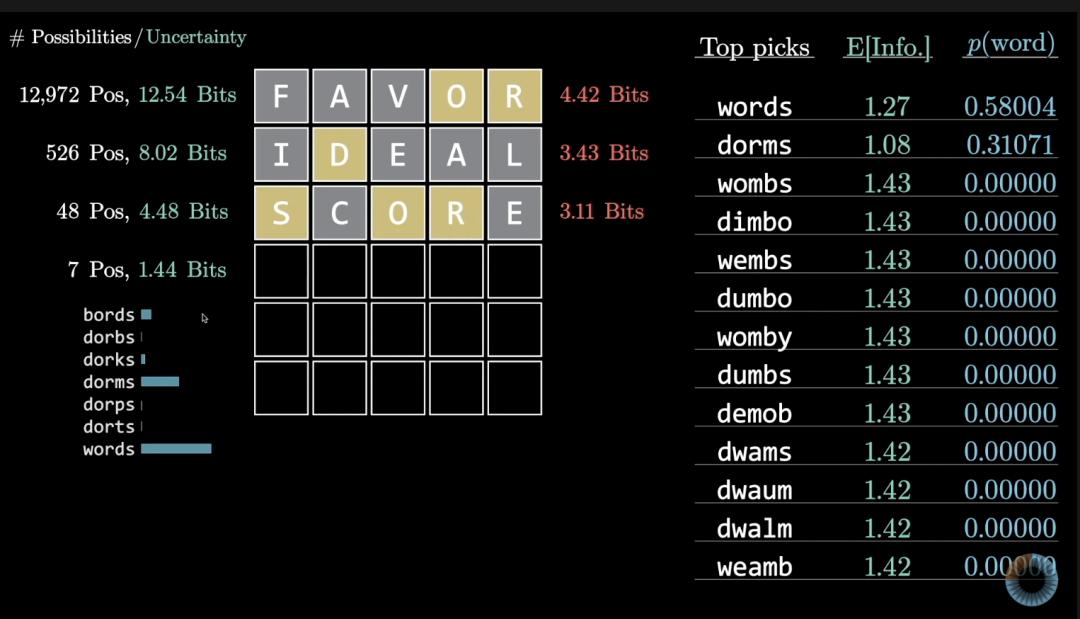
优化后的成绩到了3.601,平均节省了半步。
如果加大计算量,每次根据两步搜索的结果选择单词可以进一步提高成绩。
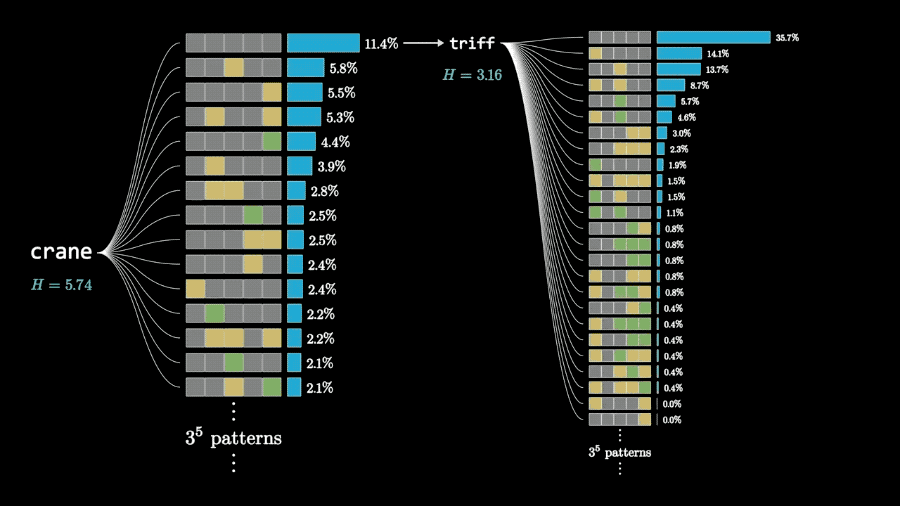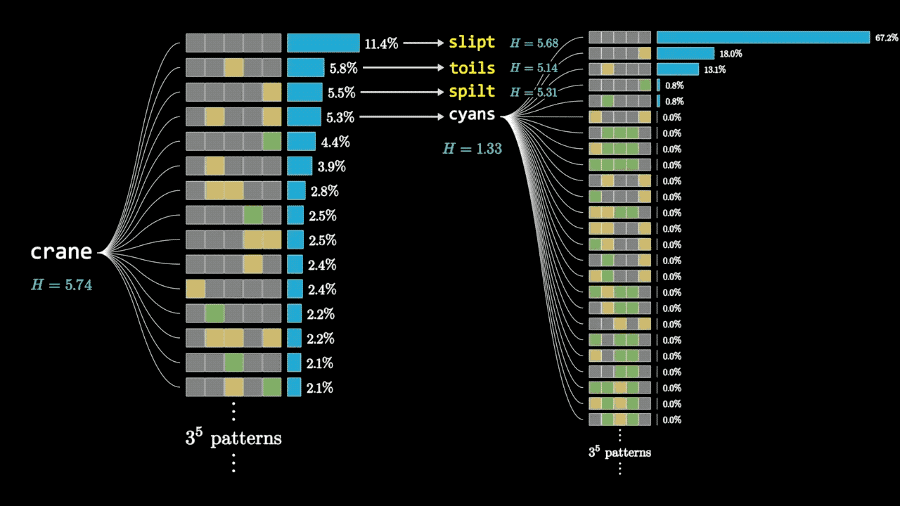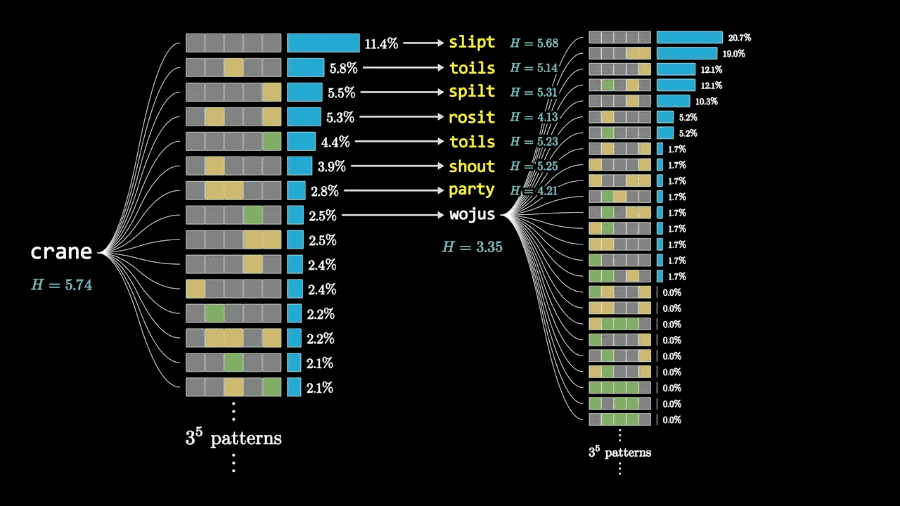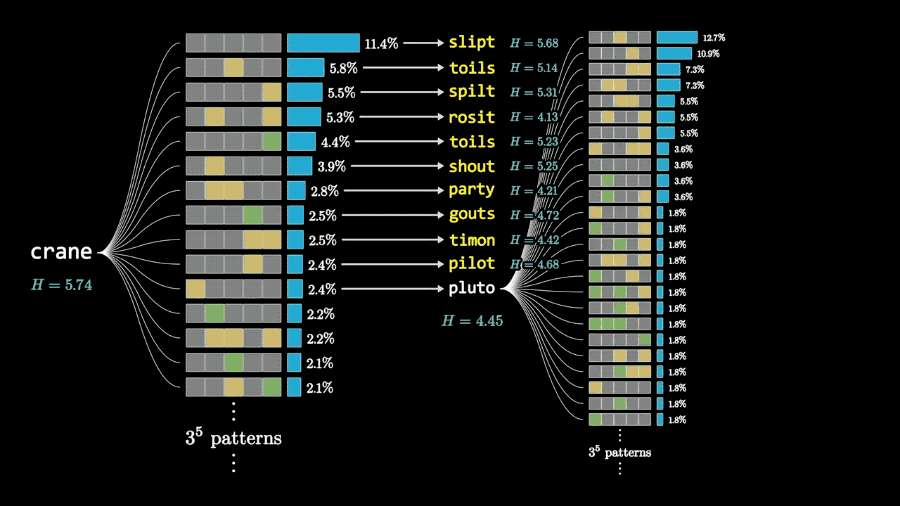
而且根据两步搜索的计算结果,3Blue1Brown认为能获得最大信息量的开局单词是crane。
此外还可以让程序知道具体哪2315个单词真的是在答案列表里的,用上所有这些技巧后,成绩再次提升到3.438。
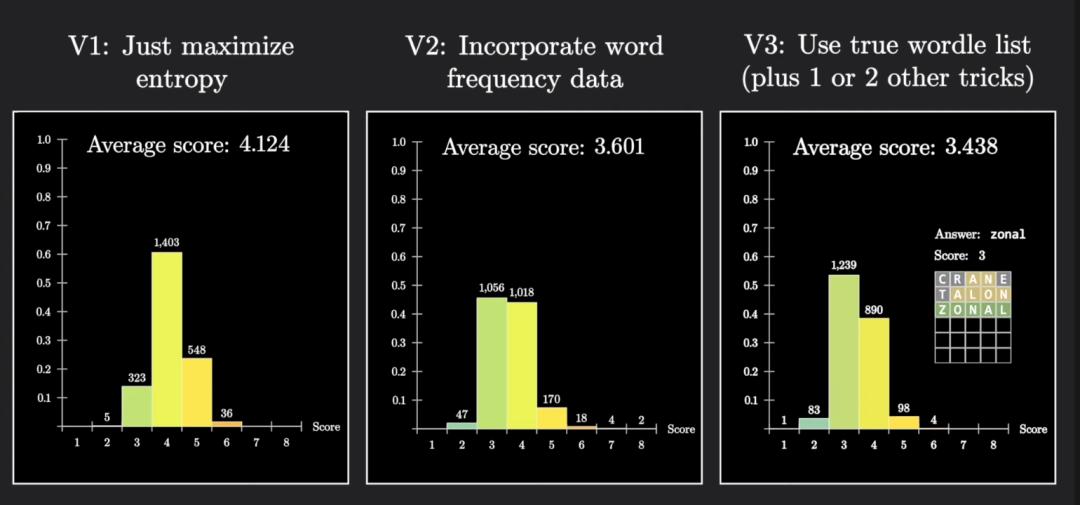
实际上这个成绩的理论极限就不可能低于3。
2315种答案意味着有11.17比特的不确定性,而暴力搜索后,前两步能获得的最大信息量在10.01比特,还剩下1.16。
也就是说第三步的难度比二选一还要难一点,没有算法能保证每次都正确。

不过3Blue1Brown还是找到了新办法进一步提升成绩。
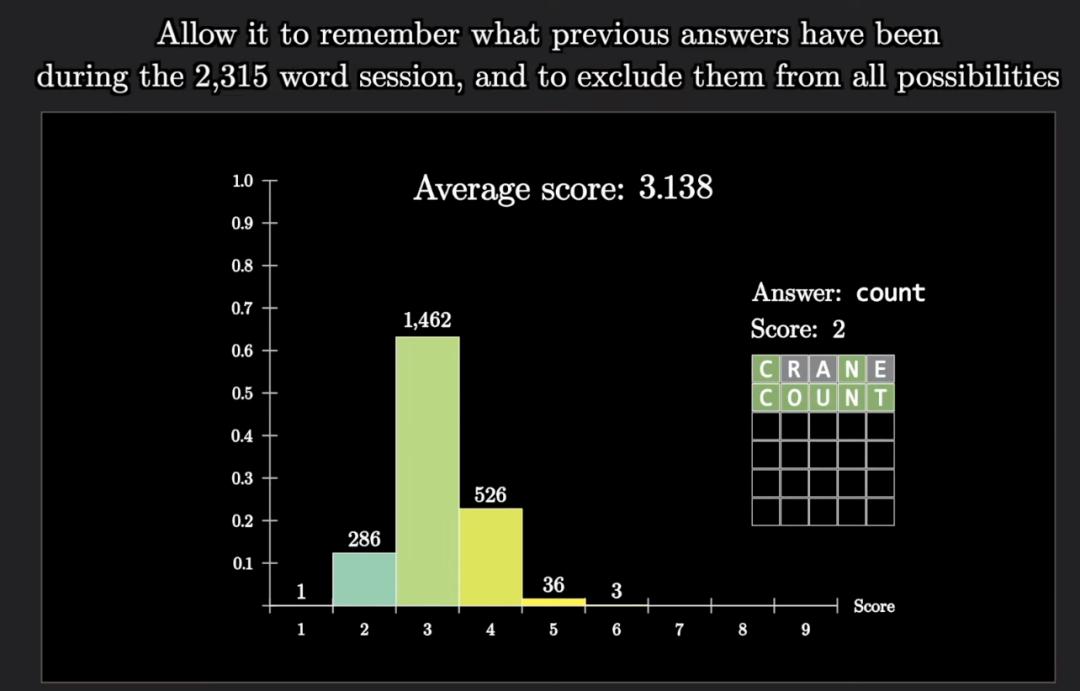
让程序记住每个正确答案,并在下一局中把猜过的单词排除出去,最终成绩到达3.138,逼近了理论极限。
看完整个视频后,有网友表示学到的信息论知识比上课学到的还多。
也有很多人对到底哪个单词才是最佳开局展开了讨论。
虽然两步搜索的结果是crane,不过3Blue1Brown也不确定对于人类玩家来说是不是最佳开局单词。
毕竟实际游戏中人类很难像程序一样算出第二步的情况。
对于人类来说,soare和tares都是很好的开局。
还能挑战变态模式
程序写好后,3Blue1Brown还做了更多尝试,比如原版Wordle的困难难度,成绩是3.562,
还有一个Wordle变态版Absurdle,这个版本不再限制尝试次数,但变态之处在于游戏AI会与玩家对抗。
玩家猜测一次后正确答案就会变化,在所有反馈可能性中挑选信息熵最大的那个,就像是在躲避玩家的猜测。
Absurdle的作者之前还开发过一个对于这个变态版Wordle,结果3Blue1Brown的程序也挑战成功。

如果你看到这里也想挑战这个变态版试试,可以复制下方链接或点击阅读原文~
视频传送门:
https://www.youtube.com/c/3blue1brown/videos
原版游戏地址:
https://www.powerlanguage.co.uk/wordle
变态版游戏地址:
https://qntm.org/files/absurdle/absurdle.html
— 完 —
原标题:《数学大神攻克猜字游戏Wordle,求解算法成绩逼近理论极限,连信息论都用上了》



